With the passage of the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), the identification of personal data has gained a lot of attention in 2018. More and more companies struggle with finding PII manually when it comes to Discovery and Data Breach Investigations – it is just too inaccurate, ineffective and time consuming. But there is light on the horizon: solutions like ayfie Inspector and ayfie Supervisor can support and automate these processes. We recently held a webinar on the topic “Automating the identification of PII”. This blogpost summarizes the key takeaways of the webinar.

When do reviews require personal data identification?
The short answer is “Almost always.” US and international regulations mandate that organizations take reasonable steps to identify, secure and prevent disclosure of personal data. It is especially the case if somebody is working on a data breach case, with finance or life sciences data. But it was already a hot topic in Discovery and other Enterprise use cases before the wave of massive data breaches and the associated laws passed in all 50 states in the US.
Common use cases amongst our clients are:
- Data breach investigation responses to regulators and individuals
- During discovery review, prior to production
- During FOIA review, prior to disclosure
- Enterprise GDPR Compliance
Companies who use solutions to automate the identification of personal data, ensure that it makes everyone's lives on their team a lot easier. Plus, it is a lot less error prone if they have an automated way of tagging and displaying data to begin with.
GDPR as an umbrella set of PII, PHI, PCI etc.
GDPR often does apply in cases of US data breach and eDiscovery. It is an umbrella or macro set of PII (Personally Identifiable Information), PHI (Protected Health information) and PCI (Personal Credit Information). GDPR applies to almost every company as it is common for companies worldwide, to have European data in their data collections.
GDPR includes, amongst others:
- Web data such as location, cookie data, IP & MAC address, RFID data
- Health, biometric, genetic, racial or ethnic data
- Religious or political belief
Companies who are already identifying and reporting on all the Personal Data are doing well in terms of GDPR and are well prepared for other US regulations as well.
GDPR and other regulations meant a major change in public policy. We have summarized more about the General Data Protection Regulation in this blogpost.
How ayfie identifies personal data
ayfie identifies personal data in structured and unstructured content. Structured content is, for instance, held in a database or Excel spreadsheet whereas unstructured content refers to free form natural language that can be stored in a Word document, PowerPoint file, PDF or other types of file formats.
How does it work? ayfie knows the linguistic structure of each language. It starts at the sentence and phrase level by identifying each part of speech. The system then normalizes terminology and recognizes synonyms. Following that, it extracts, normalizes and classifies - people, locations, organizations, key terms, dates and many other entities without needing to first train itself.
The following graphic illustrates ayfie’s composite hierarchical approach – an approach that is much more sophisticated than pure machine learning:

ayfie builds its indexes/models by dissecting language using dictionaries and local grammar libraries. And then, it uses machine learning to extrapolate from the knowns to the unknowns. It is all based on the natural structure of language instead of treating language as disconnected symbols or a “bag of words.”
An example we can all relate to involves resumes or CVs: Companies that are receiving CVs through HR or hiring managers, send those out to individuals on their team who might be helping interview the candidates. Within a short timeframe, companies can have hundreds of resumes coming in and circling around within the organization. They might be stored in central locations but employees might be passing on CVs to other team members via email, Slack, SharePoint etc. So, the question for companies is: How to manage all this unstructured applicant data in this repository? This is a challenge without the right automation technology.
What ayfie’s solution looks like
The following screenshot shows a dashboard that is used for Enterprises.
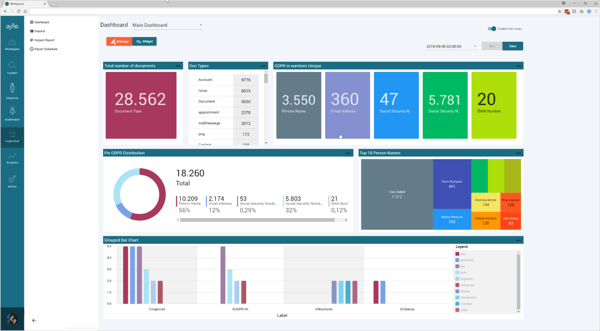
The earlier in the information lifecycle companies know where they are storing Personal Data, the better equipped they are to protect it and avoid data breaches to begin with. If personal data does become compromised, they are much better equipped to respond. If personal data has to be collected for specific reasons, e.g. for eDiscovery, companies can avoid over-collection by pre-tagging the PII and PHI. And finally, when collection is necessary (for instance in Life Science and Finance), companies at least know where the data is stored within the organization, making the privilege and redaction reviews much easier.
The webinar also talks about how ayfie Inspector indexes, understands and organizes massive amounts of content within the Relativity® ecosystem. More information and screenshots can be found here.
Learn more about how ayfie can help with personal data identification
As mentioned in the beginning, this blogpost gives a quick overview of the key takeaways from the webinar. If you want to dive deeper into the topic or see more examples and screenshots of ayfie’s solution, the webinar will be very interesting for you.
Of course, you can also always get in touch with us for any questions and get your personal demo of ayfie Inspector and ayfie Supervisor.

Photo credit header image: Cifotart via Fotolia